{itemname}
{itemname}
香港二樓書店 > 今日好書推介
格雷的五十道陰影I:調教(電影封面版)
定價127.00元
8
折優惠:
HK$101.6
●二樓推薦
●文學小說
●商業理財
●藝術設計
●人文史地
●社會科學
●自然科普
●心理勵志
●醫療保健
●飲 食
●生活風格
●旅 遊
●宗教命理
●親子教養
●少年讀物
●輕 小 說
●漫 畫
●語言學習
●考試用書
●電腦資訊
●專業書籍
使用Python搜刮網路資料的12堂實習課
沒有庫存
訂購需時10-14天
9789864345212
何敏煌,葉柏漢,顏凰竹
博碩
2020年9月30日
173.00 元
HK$ 147.05
詳
細
資
料
ISBN:9789864345212
規格:平裝 / 352頁 / 17 x 23 x 1.84 cm / 普通級 / 單色印刷 / 初版
出版地:台灣
分
類
電腦資訊
>
程式設計
>
SQL
同
類
書
推
薦
手術刀般精準的FRM - 用Python科學管控財金風險(實戰篇)
手術刀般精準的FRM:用Python科學管控財金風險(基礎篇)
Python桌面開發王者:Qt 6最強實例貫穿開發
Python+Office辦公自動化實戰
Python 資料結構×演算法 刷題鍛鍊班:234 題帶你突破 Coding 面試的難關
其
他
讀
者
也
買
從 0 到 Webpack:學習 Modern Web 專案的建置方式(iT邦幫忙鐵人賽系列書)
與成功有約:高效能人士的七個習慣(全新修訂版)
人工智慧在台灣:產業轉型的契機與挑戰
決心打底!Python 深度學習基礎養成
僕人領導學:領導者與跟隨者互惠雙贏的領導哲學
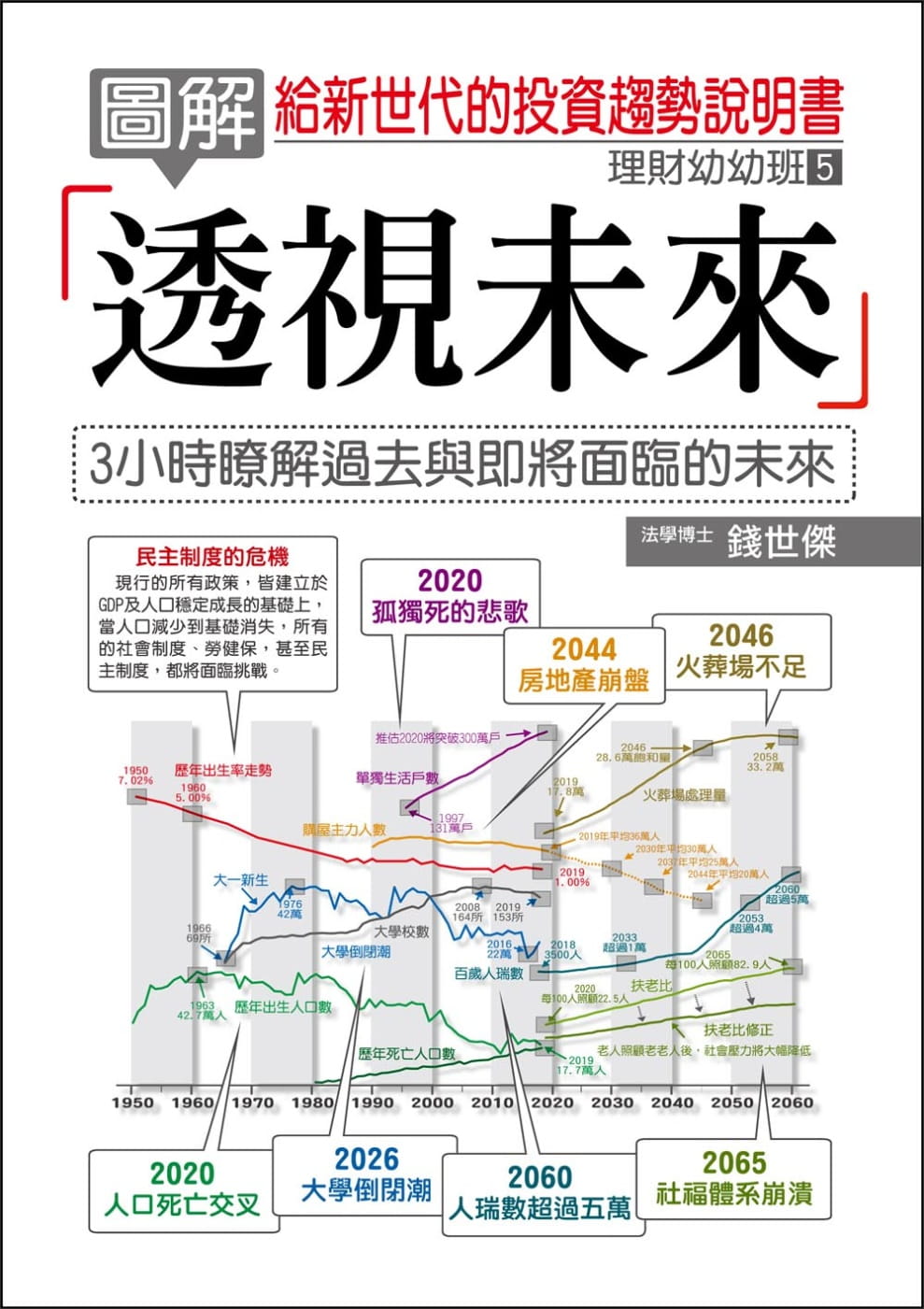
圖解透視未來:給新世代的投資趨勢說明書
內
容
簡
介
網路爬蟲是AI範疇中,
取得資料與儲存的一項重要技能,
而Python是爬蟲過程中相當好用的工具
全書以簡單的Python程式為主軸,讓您可以輕鬆學會如何利用Python的模組擷取公開的網站資料、網頁內容,並建立自己的自動化爬蟲程式,增進您在網路上搜刮資料的能力與效率,是已具有Python基礎的學習者最佳的爬蟲入門工具書。
在本書中我們將學會使用以下的Python開發環境、模組及框架:
Thonny Jupyter Notebook requests
json csv re
xlrd BeautifulSoup Selenium
sqlite3 mysql pymongo
pyinstaller Scrapy pyautogui
並學習如何擷取以下的幾種網站:
?大學網站的焦點新聞頁面?? ??政府公開資訊網站
?即時新聞網站標題、內容、圖片?? ??汽車網站之車款資訊及二手車在庫資訊
?銀行網站之匯率資料擷取?? ??中央氣象局之氣溫觀測資訊
?Ptt八卦版年齡宣告按鈕及Ptt討論區貼文擷取?? ??網路書店暢銷書排行榜
?股市網站財經新聞?? ??線上購物網站產品資訊
?名言佳句範例網站?? ??台灣證券交易所股票資訊
?Dcard梗圖下載?? ??台灣運彩官網資訊
?Mobile01討論區貼文?? ?
本書特色
?了解網站、網頁、瀏覽器間的關係,認識爬蟲程式
?了解網路上格式HTML/CSV/JSON/XLSX
?使用requests模組取得網路上的資料
?擷取及解析JSON及CSV格式資料檔案
?利用Regular Expression及BeautifulSoup模組剖析網頁資料
?活用Chrome開發人員工具找出網頁中特定資料的CSS選擇器內容
?使用Selenium自動化工具擷取動態網頁
?把擷取的資料儲存到MySQL及MongoDB資料庫
?利用排程器做到自動化資料擷取及通知的功能
?透過Scrapy框架建立爬蟲程式,大量搜刮資料
目
錄
第1堂 認識網站與網路爬蟲原理
1-1 什麼是爬蟲程式
1-2 瀏覽器與網頁伺服器
1-3 從網站下載資料的概念與原理
1-4 本書程式執行環境的建立
1-5 習題
第2堂 快速了解網路資料格式
2-1 HTML/CSS
2-2 CSV
2-3 JSON
2-4 XLS/XLSX
2-5 習題
第3堂 擷取網頁資料基礎
3-1 requests模組介紹與使用
3-2 資料檔案存取
3-3 網路公開資訊CSV格式讀取實例
3-4 網路公開資訊JSON格式讀取實例
3-5 習題
第4堂 HTML網頁剖析基礎
4-1 使用Regular Expression剖析網頁
4-2 使用BeautifulSoup剖析網頁
4-3 新聞網站之擷取與儲存
4-4 網頁圖形檔之擷取與儲存
4-5 習題
第5堂 HTML網頁剖析實務
5-1 Jupyter Notebook安裝與使用
5-2 Chrome開發人員工具
5-3 活用表單查詢存取資料
5-4 新聞網站內容之擷取與儲存
5-5 習題
第6堂 CSS選擇器基礎與活用
6-1 CSS 選擇器介紹
6-2 Selenium安裝與使用
6-3 動態網頁資料擷取
6-4 表單登入網頁擷取
6-5 習題
第7堂 MySQL資料庫儲存
7-1 資料庫與SQL
7-2 SQLite資料庫簡介與操作
7-3 MySQL資料庫系統安裝
7-4 MySQL資料庫操作實例
7-5 習題
第8堂 MongoDB資料庫操作
8-1 MongoDB安裝與操作
8-2 使用Python儲存資料
8-3 使用Python讀取資料
8-4 MongoDB資料庫應用實例
8-5 習題
第9堂 自動化資料擷取
9-1 自動化資料擷取程式
9-2 電子郵件通知實作
9-3 建立可執行檔
9-4 作業系統排程設定
9-5 習題
第10堂 Scrapy初階
10-1 Scrapy簡介與安裝
10-2 Scrapy Shell測試與練習
10-3 Scrapy專案檔案的編輯與執行
10-4 爬取網頁內容並儲存到資料庫
10-5 習題
第11堂 Scrapy 爬蟲實務
11-1 學校網頁資料爬取實例
11-2 新聞網站資料爬取實例
11-3 PTT討論區爬取實例
11-4 習題
第12堂 爬蟲實戰技巧及實例
12-1 活用pyautogui模組和網頁互動
12-2 Dcard梗圖爬取實例
12-3 下載無限捲動網頁內容
12-4 MOBILE01討論區爬取實例
12-5 車商二手車資料下載實例
12-6 習題
附錄 反爬蟲與反反爬蟲的戰爭
a-1 網站的robotstxt
a-2 User-Agent
a-3 頻繁的request請求
a-4 JavaScript程式動態產生的網頁
a-5 我不是機器人驗證
a-6 CAPTCHA和reCaptcha驗證碼
a-7 人機合作爬蟲程式解決驗證碼問題
書
評
其 他 著 作